
Integers still rule.
There is a little debate or controversy regarding the right approach for assigning surrogate keys, assuming, of course you’re not mired in the debate whether or not to create data models in the first place. I guess if you aren’t creating data models, this is not for you.
In the dbt community, many engineers prefer a hash algorithm for assigning a surrogate key. ‘dbt’, for example, has a feature in dbt_utils that performs this function nicely, including handling null values, which are often encountered when performing surrogate replacement on fact table deliveries. This approach has the benefit of making models simple, especially for fact tables. The dbt function converts everything to a string, inserts a default value in the case of a null, and then uses the snowflake md5 function to generate a long string as the surrogate key. For me, the appeal of this approach is that I do not have to go looking for the surrogate key value when I need it. The function is ‘deterministic’ – so as long as I use the same function when assigning the key (typically when building a dimension), and when “looking it up” or assigning it in a fact table delivery the process looks simple.
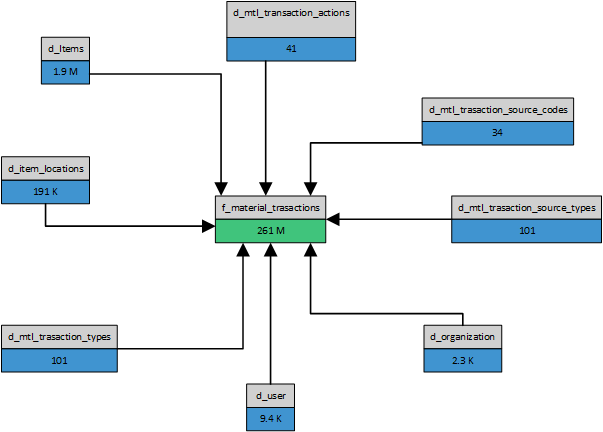
I was tempted by this simplicity, so I set out to do some testing using a simple star schema data model. This is what it looks like, including row counts. This is based on material transactions in Oracle EBS.
Here is an example of what the model to build a dimension looks like using the generate_surrogate_key macro in the dbt_utils package:
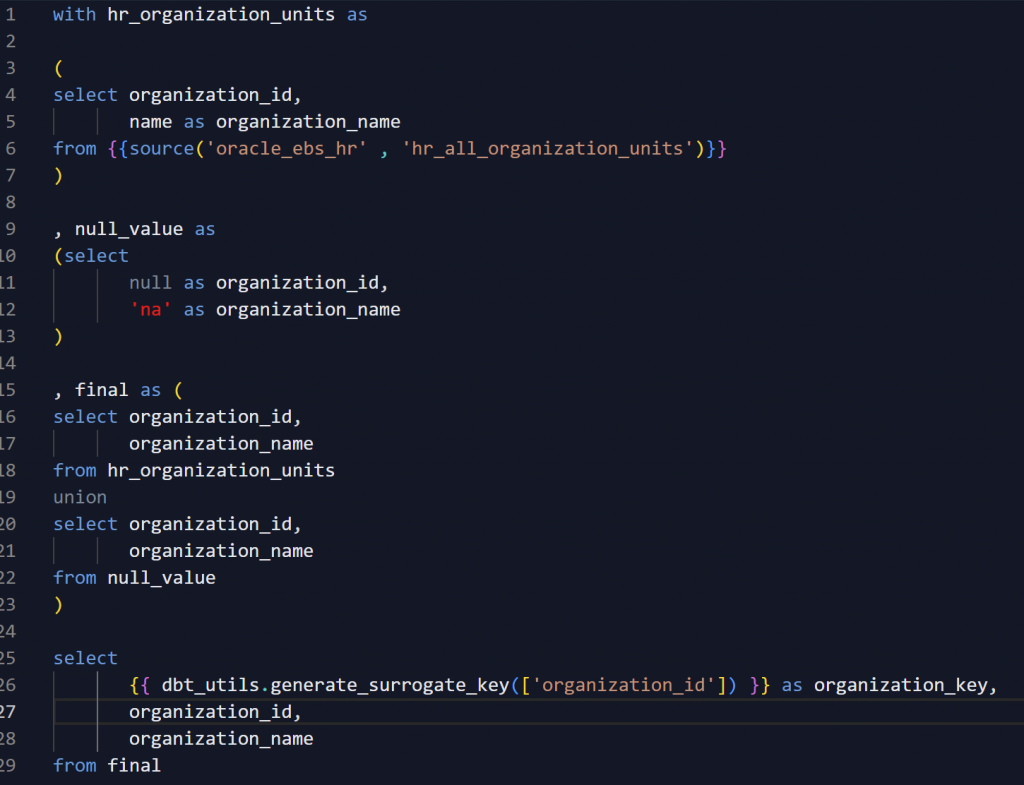
This is a very simple model that delivers the d_organization table shown in the drawing to the data warehouse. Since it’s a dimension, I added a row for the null value. That way, when using this dimension in reporting, the dimension will contain a record for the null value, matching any potential nulls in the fact table, and I can use inner joins when querying.
Here is an example of how this approach looks when delivering a fact table:
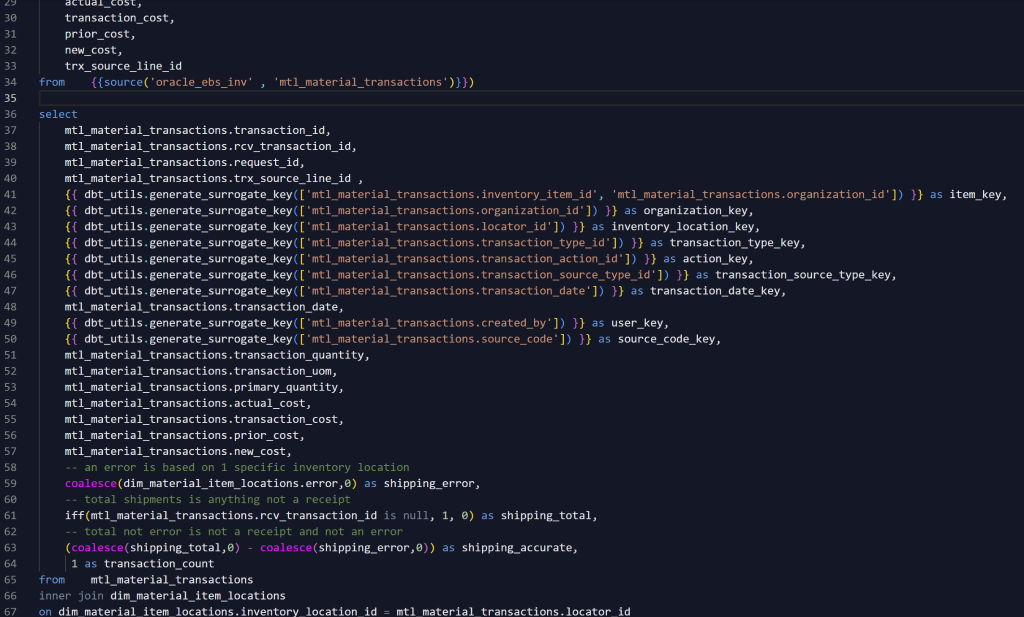
The first thing I liked was how simple the model was. Since I do not need to look up keys in dimension tables, none of those expressions are defined. And the final query does not need any joins to dimension tables, and as a result, the model is very simple. However, in order to facilitate reporting, I needed to use a dimension to perform some transformations. So I still needed to “look up” one dimension, but this model was still very simple.
But I noticed that building models was slower. In some cases much slower, which of course means higher compute costs. I looked at the compiled code and this is what I found:

It makes sense to me that this would be slower – so many functions! I also expected these keys to use more storage, but maybe not as much as it turned out to be – almost double in this case. When I was at Snowflake Summit in June, a peer mentioned using the md5_binary function to generate a binary hash to use as a surrogate key. They suggested it would be much smaller. So I tested that. I did not go to the trouble of handling null values, which would be necessary – I just wanted to see if they took up less space, and if this approach would be faster. Space was almost the same, and performance was very similar and this was disappointing. Also, some reporting tools like PowerBI do not support this data type, so maybe this was never a real option, anyway.
So then I used what I would call a traditional ETL framework, largely based on what I would call traditional ETL design patterns using PowerCenter or DataStage, where surrogate key replacement is performed with lookups when delivering fact data. However, there is no standard functionality in dbt to use when assigning or creating the surrogates when building dimensions. I’ve seen a couple of examples where database sequences are used, but those seem to create complexity. For example – unless forced, I want dbt to manage the target tables, dropping and recreating them every time, so using a sequence is …complicated.
Meanwhile, I’ve been using row numbers, and I think they work great. Here’s the same dimension model using row_number:
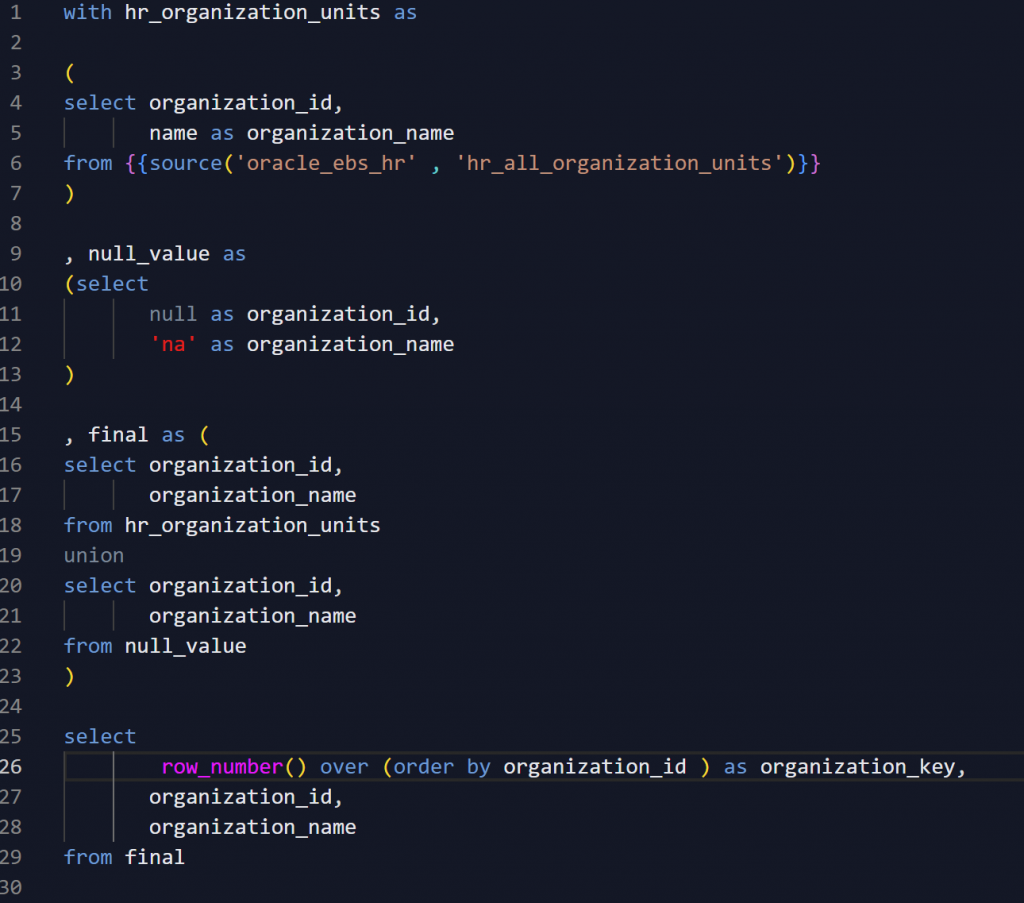
As you can see, the dimension models are pretty much the same, but they run faster, and take up less space. They are based on the assumption that they will be built from scratch each time (eg, truncate and load), but I already prefer this approach for other reasons – like ongoing maintenance, development and support, maybe I’ll say more about this another time.
Fact models are more complex, but they build much faster, and take up much less space than the md5 options. The surrogate key replacement approach is to include lite dimension queries in the model, and then join them to the fact data using the natural keys, while delivering the surrogate keys.
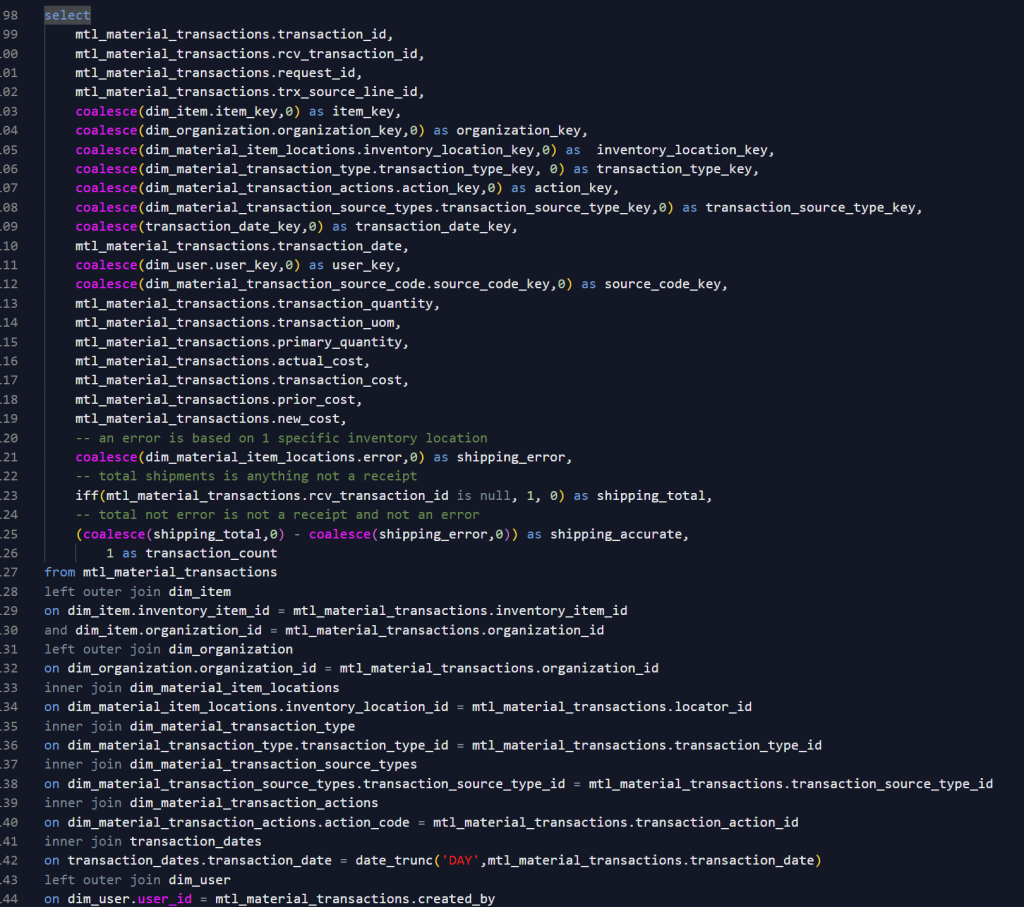
Meanwhile, the integer keys are supported by everything and probably support better query performance by reporting and downstream transformations. As an aside, I use the outer join and coalesce combination to assign the na or missing key to the 0 surrogate. That way, I can use inner joins universally in reporting.
For those interested in seeing the raw performance numbers for the tests I performed on these dbt models, here they are:
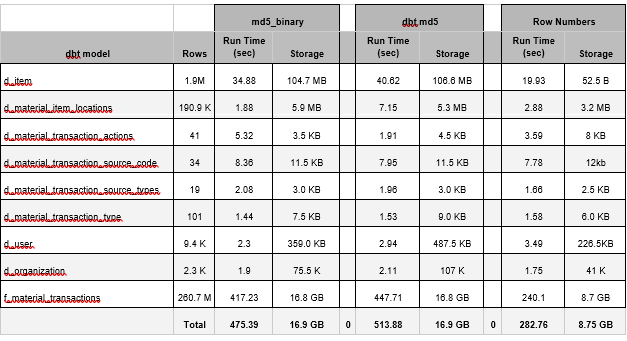
As you can see here, using either of the md5 options to assign surrogate keys resulted in roughly double the run times of models using the row number approach, and this is for a single star schema, and only includes the dbt model run times. Assuming a similar ratio for query and reporting, the cost benefits associated with the row number approach are significant, and soft benefits to users like database performance are also significant.
There may be a day in the future where this approach runs into trouble, like maybe a very large and wide fact table with many dimensions, but so far this has not happened. In fact, I have been surprised again and again, expecting to run into a limitation, but it just has not happened, and 90% of the time I have assigned xs non-clustered warehouses, the absolute lowest cost option in Snowflake.
I would love to hear your thoughts and questions, good or bad. Looking forward to it.
EmL
elealos@quantifiedmechanix.com